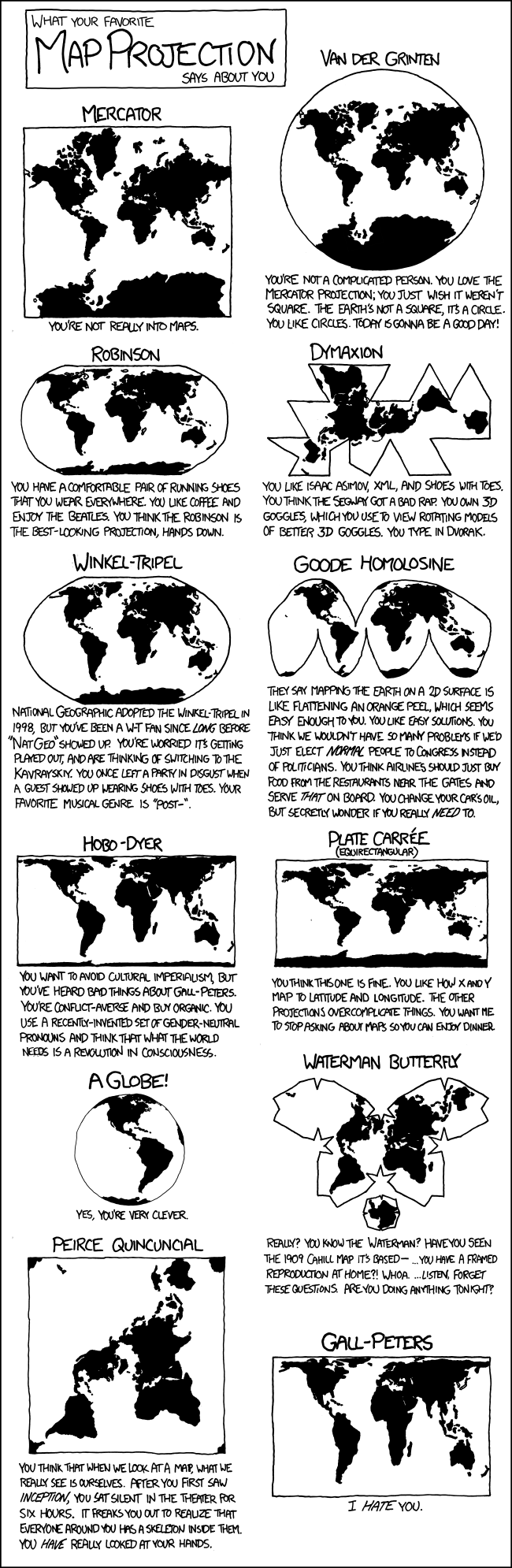
Geodaten in Python - mehr als nur eine Alternative zum GIS¶
(Quelle: Carlos Cilleruelo auf towardsdatascience.com)
Das Arbeiten mit Geodaten ist eine zentrale Komponente der Umweltdatenverbeitung. Außerhalb Geographischer Informationssysteme (GIS) gibt es mächtige Werkzeuge, um direkt in Python Geodaten zu analysieren und zu visualisieren. Im Gegensatz zur Erstellung einfacher Karten im GIS ist das zwar mit verhältnismäßig viel Code verbunden. Dafür hat man aber mehr Flexibilität und kann die Erstellung von Karten direkt in weitergehende Analysen einbetten. Auch die automatisierte Erstellung von Karten geht mit Python leichter.
In diesem Kapitel werden wir Euch im Wesentlichen "Rezepte" vorstellen, wie Ihr unterschiedliche Typen von Geodaten in Eure Python-Umgebung laden und damit arbeiten könnt. In diesem Kontext werden wir auch ein paar grundlegende Begriffe aus den Bereichen GIS und Kartographie rekapitulieren.
(Falls Du die schöne Karte oben nachbauen möchtest: Hier gibt es die Anleitung.)
Karten erstellen in Python...eigentlich gar nichts Neues?¶
Ihr habt in diesem Kurs bereits matplotlib kennengerlernt. Mit matplotlib könnt Ihr Punkte, Linien oder Flächen in ein Koordinationsystem plotten - und um nichts anderes handelt es sich bei einer Karte.
Beispiel: Niederschlagsstationskollektiv des Deutschen Wetterdienstes¶
import pandas as pd
Wir lesen die Metadaten der Niederschlagsstationen des DWD mit pandas ein. Nettes feature: Wir müssen die Daten gar nicht runterladen, sondern können direkt die Datei via https ansprechen.
Das Argument encoding könnt Ihr getrost ignorieren...das müssen wir angeben, damit pandas die Umlaute etc. kapiert.
fdwdgauges = "https://opendata.dwd.de/climate_environment/CDC/observations_germany/climate/daily/more_precip/recent/RR_Tageswerte_Beschreibung_Stationen.txt"
dwdgauges = pd.read_fwf(fdwdgauges, encoding="ISO-8859-1", skiprows=2,
names=["id", "from", "to", "elevation", "lat", "lon", "name","state","abgabe"])
dwdgauges.head()
Wir sehen: Die Datei enthält die geographischen Koordinaten der Stationen (lon, lat). Damit können wir die Positionen auf eine Karte plotten.
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize = (4,5), nrows=1, ncols=1)
plt.plot(dwdgauges.lon, dwdgauges.lat, "ko", ms=2, mfc="None", mew=0.5)
plt.xlabel("Longitude")
plt.ylabel("Latitude")
plt.title("DWD Niederschlagsstationen")
plt.grid()

Ganz schön viele Stationen! Und die messen alle Niederschlag?!
Manipulieren wir doch mal die Karte, indem wir z.B. diejenigen Stationen in rot darstellen, die gar nicht mehr aktiv sind. Dazu müssen wir die Zeitkomponente der Metadaten als Datum interpretieren und anschließend den dataframe mit Hilfe des to-Attributs filtern.
dwdgauges.head()
dwdgauges["fromdate"] = pd.to_datetime(dwdgauges["from"], format="%Y%m%d")
dwdgauges["todate"] = pd.to_datetime(dwdgauges["to"], format="%Y%m%d")
inactive = dwdgauges.todate < "2024-12-01"
fig, ax = plt.subplots(figsize = (4,5), nrows=1, ncols=1)
plt.plot(dwdgauges.lon, dwdgauges.lat, "ko", ms=2, mfc="None", mew=0.5)
plt.plot(dwdgauges.loc[inactive,"lon"], dwdgauges.loc[inactive,"lat"],
"ro", ms=2, mfc="None", mew=0.5)
plt.xlabel("Longitude")
plt.ylabel("Latitude")
plt.title("DWD Niederschlagsstationen")
plt.grid()

Aha...also doch nicht so viele? Aber klar: Stationen wurden über die Zeit verlegt, stillgelegt, neu gebaut und wieder stillgelegt. Wenn man die Daten verarbeiten möchte, muss aber jeder Standort eine eindeutige ID haben...da kommt dann eben über die Zeit was zusammen. Apropos Zeit...reichern wir doch mal die Karte mit einer Zeitreihe an: Zahl der Stationen von 1901 bis 2023.
import numpy as np
years = np.arange(1901,2023)
numgauges = np.zeros(len(years))
for i, year in enumerate(years):
hasdata = (year >= dwdgauges.fromdate.dt.year) & (year <= dwdgauges.todate.dt.year)
numgauges[i] = np.sum(hasdata)
fig, ax = plt.subplots(figsize = (12,4), nrows=1, ncols=4)
plt.sca(ax[0])
year = 1920
hasdata = (year >= dwdgauges.fromdate.dt.year) & (year <= dwdgauges.todate.dt.year)
plt.plot(dwdgauges.loc[hasdata,"lon"], dwdgauges.loc[hasdata,"lat"], "ko", ms=2, mfc="None", mew=0.3)
plt.xlabel("Longitude")
plt.ylabel("Latitude")
plt.title("Stationen im Jahr %d" % year)
plt.sca(ax[1])
year = 1987
hasdata = (year >= dwdgauges.fromdate.dt.year) & (year <= dwdgauges.todate.dt.year)
plt.plot(dwdgauges.loc[hasdata,"lon"], dwdgauges.loc[hasdata,"lat"], "ko", ms=2, mfc="None", mew=0.3)
plt.xlabel("Longitude")
plt.title("Stationen im Jahr %d" % year)
plt.sca(ax[2])
year = 2023
hasdata = (year >= dwdgauges.fromdate.dt.year) & (year <= dwdgauges.todate.dt.year)
plt.plot(dwdgauges.loc[hasdata,"lon"], dwdgauges.loc[hasdata,"lat"], "ko", ms=2, mfc="None", mew=0.3)
plt.xlabel("Longitude")
plt.title("Stationen im Jahr %d" % year)
plt.sca(ax[3])
plt.plot(years, numgauges, "k-")
plt.xlabel("Jahr")
plt.title("# Stationen 1901-2023")
plt.grid()
plt.tight_layout()

Fazit¶
Wir haben einen Geodatensatz eingelesen und Karten erstellt, ohne ein neues Werkzeug zu nutzen. Obendrein haben wir die Karten ganz lässig mit Zeitreihen angereichert...an sowas müsstet Ihr in einem GIS lange schrauben!
Trotzdem sind wir noch nicht zufrieden. Es wäre z.B. schön, die Landesgrenzen und ggf. Grenzen der Bundesländer mit darzustellen...
Was fehlt uns, um effizient schöne Karten zu gestalten?¶
Wir haben nun also mit Standardpaketen (matplotlib, pandas) bereits wesentliche Elemente von Karten erstellt? Was fehlt uns noch?
- Einlesen gängiger Geodaten in Vektor- und Rasterformaten
- Koordinatentransformation ("reproject")
- Effizientes Plotten spezifischer Geodatentypen- und Elemente
- Gängige GIS-Operationen
Aufgabe¶
Diskutiert mal ein paar GIS-Grundbegriffe...
- Was sind Vektordaten? Nennt zwei gängige Datenformate!
- Was sind Rasterdaten? Nennt zwei gängige Datenformate!
- Nennt mindestens drei typische GIS-Operationen mit Vektordaten.
- Wozu braucht man Projektionen (oder Spatial Reference Systems)?
Lesen und plotten von Vektordaten mit geopandas¶
Die folgende Abbildung macht noch einmal deutlich, worum es sich bei Vektordaten handelt.
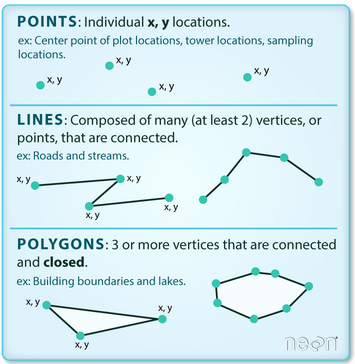
(Quelle: Colin Williams, NEON)
Typische Datenformate für Vektordaten:¶
- Shapefile (.shp),
- geojson (.json)
- GPS Exchange Format (.gpx)
- Google Keyhole Markup Language (.KML, .KMZ)
- ...
Aufgabe¶
Für welche Umweltdaten ist das Vektorformat geeignet, für welche nicht?
Lösung¶
Vektordaten sind geeignet für:
- Verwaltungeinheiten, politische Grenzen
- Straßen, andere Infrastrukturelemente
- Gebäudeumrisse
- Gewässer (Flüsse, Seen, ...)
- Habitate
- Messpunkte
- ...
Vektordaten sind ungeignet für:
- Digitale Geländemodelle
- Fernerkundungsdaten
- Daten aus Klimamodellen
- ...
geopandas¶
import geopandas as gpd
f_bundeslaender = "../data/shapefiles/VG250_LAN.shp"
bundeslaender = gpd.read_file(f_bundeslaender)
bundeslaender.head()
Puuh, 27 Spalten - ganz schön viele Attribute...naja, wir intessieren uns ja erstmal nur für die Ländergrenzen. Schnell mal gucken, ob die da sind...
bundeslaender.plot(edgecolor="black", facecolor="white")

Ok, sieht ja schon gut aus...sogar mit Hoheitsgebieten im Meer - wollten wir die haben? Egal.
Was aber bei den Achsen auffällt, ist die Größenordnung...irgendwas um 600.000 für die x-Achse und zwischen 5 und 6 Millionen für die y-Achse. Längen- und Breitengrade sind das jedenfalls nicht.
bundeslaender.crs
Aufgabe¶
Unsere DWD-Stationen liegen aber in geographischen Koordinaten (lon/lat) vor... was müssen wir tun, um die Stationen und Ländergrenzen in einer Karte darzustellen?
Lösung¶
Richtig: Wir müssen umprojizieren.
Zum Glück gibt es EPSG-Codes...¶
Mit EPSG-Codes kann man kurz und bündig Projektionen ansprechen. Ein echter Segen - dabei steht die Abkürzung für European Petroleum Survey Group Geodesy. Das haben wir also der Erdölindustrie zu verdanken...
Der EPSG Code 4326 wird für klassische geographische Koordinaten verwendet (https://epsg.io/4326).
bundeslaender2 = bundeslaender.to_crs("EPSG:4326")
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(4,5))
# ACHTUNG: Wir übergeben der plot Methode die "axes", auf der sie plotten soll!
bundeslaender2.plot(ax=ax, facecolor="None", edgecolor="tab:blue")
year = 2021
hasdata = (year >= dwdgauges.fromdate.dt.year) & (year <= dwdgauges.todate.dt.year)
plt.plot(dwdgauges.loc[hasdata,"lon"], dwdgauges.loc[hasdata,"lat"], "ko",
ms=3, mfc="None", mew=0.3)
plt.xlabel("Longitude")
_ = plt.title("Stationen im Jahr %d" % year)

Oder wir projizieren die Stationdaten um. Dazu müssen wir den Dataframe in einen sog. GeoDataFrame umwandeln.
gdf = gpd.GeoDataFrame(dwdgauges,
geometry=gpd.points_from_xy(dwdgauges.lon, dwdgauges.lat), crs="EPSG:4326")
gdf_utm = gdf.to_crs(bundeslaender.crs)
fig, ax = plt.subplots(figsize=(4,5), nrows=1, ncols=1)
bundeslaender.plot(ax=ax, facecolor="None", edgecolor="tab:blue")
year = 2021
hasdata = (year >= dwdgauges.fromdate.dt.year) & (year <= dwdgauges.todate.dt.year)
plt.plot(gdf_utm.geometry.x[hasdata], gdf_utm.geometry.y[hasdata], "ko",
ms=3, mfc="None", mew=0.3)
_ = plt.title("Stationen im Jahr %d" % year)

Rasterdaten lesen mit rasterio¶
rasterio ist ein Paket zum Lesen, Schreiben und Verarbeiten von Rasterdaten. Eine ausführliche Dokumentation des Pakets findet Ihr hier.
Wir werden es in diesem Kurs aber zunächst nur zum Lesen eines Rasters verwenden. Unser Ziel ist es, unsere schöne Deutschlandkarte mit einer Topographie zu hinterlegen. Es gibt für die meisten Bundesländer mittlerweile frei verfügbare hochaufgelöste (1x1 m) Digitale Geländemodelle (DGM; engl. digital elevation model, DEM) . Außerdem gibt es hochauflösende globale DGM mit Auflösungen zwischen 20 und 30 Metern (u.a. SRTM, ASTER). Eine "optimale" Kombination von SRTM und ASTER auf europäischer Ebene gab es bei der Europäische Umweltagentur EEA hier, der Datensatz ist mittlerweile aber nicht mehr verfügbar...
Für eine deutschlandweite Darstellung sind diese Produkte aber zu hoch aufgelöst und damit ineffizient (Speicher, Rechenbedarf). Wir nutzen daher ein Produkt, das auf eine Auflösung von 1x1 km für ganz Europa "resampled" wurde. Es beruht auf dem globalen Datensatz GTOPO30. Auch diesen Datensatz haben wir bei der EEA hier heruntergeladen.
import rasterio
import datetime as dt
rio = rasterio.open('../data/raster/elevation1x1_new.tif')
type(rio)
Das erhaltene Objekt rio ist vom Typ rasterio.io.DatasetReader und wir können es ein wenig interviewen, ohne überhaupt etwas in den Arbeitsspeicher geladen zu haben.
print("Beginn des Interviews am %s\n" % dt.datetime.now().strftime("%d. %B %Y"))
print("Wie heißen Sie?\n\t", rio.name)
print("Wie viele Zeilen und Spalten haben Sie?\n\t%d Zeilen und %d Spalten " % (rio.height, rio.width))
print("Wie lautet Ihre Bounding Box?\n\t%r" % (rio.bounds,))
Vor allem aber die Frage, die wir jedem Geodatensatz stellen müssen: Welche Projektion ("coordinate reference system", CRS)?
print("Was ist Ihr CRS?\n\n%r\n" % rio.crs)
print("Vielleicht eine etwas kürzere Antwort?\n\t...%s" % rio.crs.to_dict()["proj"])
Wir haben es also mit laea, der Lambert Azimuthal Equal Area, also einer flächentreuen Projektion, zu tun. Nun gut, wir nehmen das einfach mal so hin.
Tatsächlich haben wir bislang aber noch keine eigentlichen Daten in unsere Umgebung eingelesen, sondern nur ein sog. rasterio.io.DatasetReader-Objekt generiert. rasterio bietet auf diesem Weg eine einheitliche Schnittstelle für unterschiedliche Rasterdatenformate (z.B. ESRI ASCII Grid, Erdas Imagine). Wir wollen in unserem Beispiel eine GeoTIFF-Datei einlesen.
Rasterdatenformate wie GeoTIFF sind in der Fernerkundung beliebt. Sie sind so ausgelegt, dass in einem Datensatz unterschiedliche Bänder (engl. "bands") abgelegt werden können (klassischerweise z.B. rot, grün, blau - RGB). In unserem Datensatz erwarten wir aber nur die Geländehöhe. Dies können wir verifizieren:
print("Wieviel Bänder enthalten Sie?\n\t...nur %d Band" % rio.count)
rio.count
Der Konvention des bei rasterio im Hintergrund tätigen Zugpferds GDAL (https://gdal.org) folgend, wird das erste Band mit 1 indiziert - nicht wie bei Python mit 0. Tja, das muss man erstmal wissen...oder ausprobieren...oder googlen.
Wir lesen nun die eigentlichen Rasterdaten ein und nennen die Variable elev.
elev = rio.read(1)
type(elev)
Schön, wir haben es also mit einem ganz normalen numpy-Array zu tun. Die Sorte kennen wir ja schon.
print("Shape des Arrays: ", elev.shape)
print("Minimum: %s, maximum: %s" % ( elev.min(), elev.max() ))
Aufgabe¶
Stopp...die maximale Geländehöhe in Europa soll 187 Meter betragen? Überlege, was für ein Missverständnis/Problem hier vorliegen könnte. Lies ggf. die Metadaten (Link). Schlage eine pragmatische Lösung vor.
Lösung¶
In den Metadaten finden wir, dass ein z factor für den Datensatz genutzt wurde. Wir müssen also den Array mit dem Wert 10 multiplizieren.
elev = rio.read(1) * 10.
Testplot¶
cp = plt.imshow(elev, cmap=plt.cm.terrain,
extent=(rio.bounds.left, rio.bounds.right, rio.bounds.bottom, rio.bounds.top))
_ = plt.colorbar(cp)

Soweit, so gut: Wir haben einen Rasterdatensatz mit rasterio eingelesen, wir kennen sein CRS und können den Datensatz mit imshow plotten.
Synthese: Stationsmessnetz mit Ländergrenzen und Topographie plotten¶
Wir plotten im CRS des Rasterdatensatzes, weil wir uns mit dem Thema Projektion bzw. Warpen von Rasterdaten nicht befassen wollen. Wir bringen also zunächst unsere Vektordaten (Bundesländer und Stationsmessnetz) in das CRS des Rasterdatensatzes.
bundeslaender_laea = bundeslaender.to_crs(rio.crs)
gdf_laea = gdf.to_crs(rio.crs)
Und weil die Topographie mit einem Hillshade immer schicker aussieht, nutzen wir noch das Hillshade-Raster, welches uns auf der gleichen EEA-Seite zur Verfügung gestellt wird (Link). Das Hillshade-Raster plotten wir ebenfalls mit imshow, aber mit einer Tansparenz (Parameter alpha).
riohs = rasterio.open('../data/raster/hillshade1x1/hillshade1x1.tif')
hillsh = riohs.read(1)
fig, ax = plt.subplots(1,1, figsize=(7,7))
ax.set_aspect("equal")
# Rasterdaten
plt.imshow(elev, cmap=plt.cm.terrain,
extent=(rio.bounds.left, rio.bounds.right, rio.bounds.bottom, rio.bounds.top))
plt.imshow(hillsh, cmap=plt.cm.gray, vmin=0, vmax=200, alpha=0.5,
extent=(riohs.bounds.left, riohs.bounds.right, riohs.bounds.bottom, riohs.bounds.top))
# Vektordaten
plt.plot(gdf_laea.geometry.x[hasdata], gdf_laea.geometry.y[hasdata], "ko",
ms=3, mfc="None", mew=0.9)
bundeslaender_laea.plot(ax=ax, facecolor="None", edgecolor="black")
# Für so eine schöne Karte wollen wir keine hässslichen Achsen
ax.xaxis.set_visible(False)
ax.yaxis.set_visible(False)
## Zoomlevel steuern
plt.xlim(4.1e6, 4.6e6)
plt.ylim(2.9e6, 3.4e6)
_ = plt.title("DWD Niederschlagsmessnetz", fontsize=12)

Vertiefungsaufgabe für die Coding-Werkstatt¶
Fertige auf Basis der heute behandelten Inhalte und Daten eine Karte für Dein Heimatbundesland an, in welchem folgende Informationslayer vorhanden sind:
- Topographie
- Landesgrenzen
- Hauptstadt
- wesentliche Fließgewässer
- ...
Such Dir ggf. erforderliche Geodaten selbst aus dem Netz!
Weiteres Studium¶
- Introduction to Python GIS (Link): 3-day course organized by CSC Finland – IT Center for Science