Nicht so eindimensional! Vom Arbeiten mit multi-dimensionalen Daten¶
 (Quelle:
(Quelle: Dimensionen von Umweltdaten¶
Eindimensional¶
Bislang haben wir in diesem Kurs viel mit Zeitreihen gearbeitet. Zeitreihen sind ein Beispiel für eindimensionale Daten: Es wird die Dynamik einer oder mehrerer Variablen entlang der Dimension "Zeit" betrachtet.
Zweidimensional¶
In den Umweltwissenschaften haben wir es auch oft mit mehrdimensionsionalen Daten zu tun: So sind Umweltvariablen wie z.B. die Geländehöhe typischerweise entlang von zwei horizontalen Raumdimensionen ausgeprägt. Einen entsprechenden Datensatz nennt man dann typischerweise ein "Digitales Geländemodell" (DGM).

Dreidimensional¶
Während man die Geländehöhe über bestimmte Zeiträume als konstant annehmen kann, sind viele Umweltvariablen variabel in der Zeit und im horizontalen Raum. Beispiele sind Niederschlag, Landbedeckung, Bodenfeuchte u.v.a. Solche Daten lassen sich dann dreidimensional strukturieren, wobei die erste Dimension oft die Zeitdimension ist und die beiden anderen Dimensionen den horizontalen Raum abbilden. Das folgende Bild zeigt z.B. den zeitlichen Verlauf der Waldbedeckung in Borneo.

Ein anderes Beispiel für einen dreidimensionalen Datensatz ist der Zustand eines Systems entlang aller drei Raumdimensionen, also z.B. die Temperatur der Atmosphäre in Länge, Breite und Höhe, oder die Bodenfeuchte in einem Einzugsgebiet in unterschiedlichen Tiefen.
n-dimensional¶
Es kann sinnvoll sein, noch weitere Dimensionen hinzuzufügen. Wenn man in einem Klimamodell der Zustand der Atmosphäre in den drei Raumdimensionen sowie der Zeit darstellt und dann noch unterschiedliche Realisationen eines Modellensembles in einem Datensatz darstellt, so hätte man z.B. fünf Dimensionen.
Aufgabe¶
Ein "array" ist, einfach gesagt, ein Datensatz mit einheitlichem Datentyp entlang beliebig vieler Dimensionen. Gib aus den folgenden mehrdimensionalen Arrays folgende Werte an:
- 1D-Array: zweites Element
- 2D-Array: zweite Zeile, dritte Spalte
- 3D-Array: zweite Zeile, zweite Spalte, äh...erste Spalte von der anderen Sorte Spalte?!
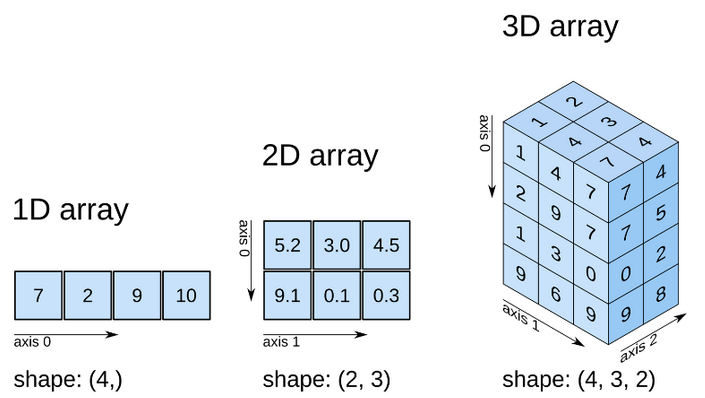
Ihr seht: Allein die Terminologie wird ab der dritten Dimension nicht ganz trivial. Der Einfachheit halber bietet es sich an, die Dimensionen einfach durchzunummerieren. In Python ist jedoch stets zu beachten: Beim durchnummerieren wird bei 0 begonnen...gucken wir uns gleich in Ruhe an.
numpy - multi-dimensionale Daten effizient verarbeiten¶
numpy ist in Python das Schlüsselmodul zum Arbeiten mit arrays entlang beliebiger Dimensionen. Kern ist der numpy.ndarray (nd steht für "n-dimensional") als Datentyp, der in unzähligen anderen Paketen zugrundegelegt wird.
import numpy as np
type( np.array([1,2,3]) )
Zum Aufwärmen: numpy in einer Dimension¶
# 1-D Array aus einer Liste erstellen
a = np.array([1,2,3,4])
Nehmen wir diesen Array einmal unter die Lupe:
print(a)
print("Number of dimensions:", a.ndim)
Elemente eines Arrays ansprechen: im Prinzip genauso wie bei einer list¶
# Das zweite Element ansprechen ( Index 1 entspricht der zweiten Position!!)
a[1]
# Das letzte Element ansprechen
a[-1]
# Alle Elemente ansprechen
a[:]
# Von der zweiten bis zur dritten Position
# ACHTUNG: Man gibt als rechte Grenze also immer die Position an, die NICHT in der Auswahl enthalten sein soll
a[1:3]
# Von Anfang bis zur dritten Position
a[:3]
# Ab der zweiten Position
a[1:]
# Von der zweiten bis zur vorletzten Position
a[1:-1]
Elemente eines Arrays manipulieren¶
# Werte von Elementen ändern
a[1] = 99
a
# Mehrere Elemente auf einmal ändern
a[:2] = 999
a
Mit Arrays arbeiten¶
Der große Unterschied zum Datentyp list: Man kann mit Arrays rechnen.
# Addition von zwei Listen
[1,2,3] + [1,2,3]
# Addition von zwei Arrays
np.array([1,2,3]) + np.array([1,2,3])
# Einen array mit aufsteigenden Werte erstellen
b = np.arange(5)
# Einen array aus Einsen erstellen, genauso lang wie `b`
c = np.ones(len(b))
print("b = ", b)
print("c = ", c)
# Eine Operation mit diesen Arrays
print("b + 2 * c = ", b + 2 * c)
Aufgabe¶
Wir definieren folgenden Array:
test = np.array([0, 1, 10, 22, 3, 99])Sage nun den Output folgender Operationen voraus (schreibe die Lösung auf ein Papier):
test[1]test[-1]test[0:3] * 2test - testtest[2:-1]test - np.arange(len(test)
Überprüfe nun Deine Lösung, indem Du in der untenstehenden Zelle den Array definierst und dann die Operationen ausführst. Vieviel Prozent hast Du richtig vorhergesagt?
Lösung¶
test = np.array([0, 1, 10, 22, 3, 99])
print(test[1])
print(test[-1])
print(test[0:3] * 2)
print(test - test)
print(test[2:-1])
print(test - np.arange(len(test)))
Exkurs: Funktionen vs. Methoden¶
Du hast jetzt schon des Öfteren mit "Funktionen" und "Methoden" gearbeitet. Du kannst Dir eine Methode vorstellen wie eine Funktion, die an einem Objekt, z.B. an einem ndarray, einem DataFrame oder einem str "dranhängt". Oft ist es egal, ob Du ein Objekt mit seiner Methode oder der entsprechenden Funktion verarbeitet.
Unverständlich? Also lieber am Beispiel:
# Ein Array
x = np.array([1,2,3])
# Anwendung der Funktion "sum"
np.sum(x)
# Anwendung der Methode "sum"
x.sum()
# Am Beispiel eines Strings
x = "Neiekoelaeuese"
# Methode replace
print( x.replace("e","") )
# Funktion replace
print( str.replace(x, "e", "") )
Fazit: Meist ist es egal, ob Du eine Funktion oder eine Methode anwendest. Oft ist es bequemer, die Methode zu verwenden, aber nicht alle Funktionen stehen als Methoden zur Verfügung. Wie immer gilt: Alles Gewöhnungssache.
numpy-Arrays mit mehreren Dimensionen¶
Wir bringen uns in shape¶
# Wir erstellen zunächst 1-D array
d1 = np.arange(24)
d1
# Und machen aus diesem einen 3-D array
# - mit 2 Elementen in der ersten Dimension,
# - 3 in der zweiten,
# - 4 in der dritten
d3 = d1.reshape((2,3,4))
d3
d1.ndim, d3.ndim
Mit dem reshape-Befehl kann man also einen Array in "Form" bringen, ihm also eine andere Dimension geben.
Wir können die "Form" des Arrays mit dem shape Befehl überprüfen.
d3.shape
Elemente auswählen¶
Das Ansprechen der Elemente eines mehrdimensionalen Arrays folgt im Prinzip der Intuition, kann aber schnell zum Braintwister werden...schaut's Euch am Besten in Ruhe an.
d3[:]
d3[0,:,:]
d3[0,1:3,:]
d3[0,1:3,2:4]
Ansonsten funktioniert auch die Zuweisung genau so wie zuvor:
d3[0,1:3,2:4] = -99
d3
# Wir können auch mit Boolschen Arrays mit gleichem shape auswählen
d3[d3>18]
Aufgabe¶
Stelle Dir den folgenden 3-D Array x mal als eine Zeitreihe von Niederschlagsgittern vor, also einer flächenhaften Darstellung des Niederschlags über die Zeit. Sagen wir: 4 Zeitschritte, 3 Zeilen, 2 Spalten.
np.random.seed(42)
x = np.random.lognormal(1, 2, size=(4,3,2)).astype(int)
x
Wähle nun der Reihe nach folgende Elemente aus:
- Alle Elemente des dritten Zeitschritts
- Alle Elemente der zweiten Spalte
- Im zweiten Zeitschritt die zweite Zeile und erste Spalte
- Alle Elemente > 0
Lösung¶
print(x[2])
print(x[:,:,1])
print(x[1,1,0])
print(x[x>0])
Die axis des Guten - Funktionen entlang von Dimensionen anwenden¶
Eine große Stärke von numpy ist die Anwendung von Funktionen entlang einer Dimension. Auch hier lieber am Beispiel der Funktion sum:
x = np.ones((3,2), dtype="int")
x
# Summe ALLER Elemente
x.sum()
# Summe über alle Zeilen (axis = 0)
x.sum(axis=0)
# Summe über alle Spalten (axis = 1)
x.sum(axis=1)
Das axis-Argument spezifiziert also immer die Dimension (Achse), die durch eine Operation "wegfallen" soll. Diese Funktionalität ist sehr mächtig und vor allem schnell und bequem.
Aufgabe¶
Nehmen wir einmal an, beim Array x handelt es sich um Messdaten für 10 Zeitschritte für 5 Sensoren. Wir stellen uns mal einen Beispieldatensatz her:
x = np.random.uniform(-1, 1, size=(10,5)).round(1)
x[x < 0] = np.nan
x
Leider fallen die Sensoren oft aus. Du möchtest Dir einen Überblick über die Datenverfügbarkeit verschaffen. Gebe für jeden Zeitschritt die Summe der Fehlwerte aus. Nutze dafür zunächst np.isnan und dann np.sum
Lösung¶
np.isnan(x).sum(axis=1)
Wie bekomme ich überhaupt meine Daten in einen numpy-Array?¶
Es gibt viele Möglichkeiten, Daten in einen ndarray zu bringen. Im Wesentlichen unterscheiden wir zwei Szenarien:
- Array selbst erstellen
- Daten aus Dateien einlesen
Arrays selbst erstellen¶
Wir haben bereits verschiedene Wege kennengelernt, Arrays mit einem definierte shape zu erstellen und damit weiterzuarbeiten.
# Array aus Einsen
np.ones(shape=(2,2), dtype=int)
# Array aus Nullen
np.zeros(shape=(2,2), dtype=int)
# Länge des Arrays sowie Start- und Endpunkt (beide inklusive) vorgeben
np.linspace(start=1, stop=11, num=5)
# Start- und Endpunkt (exklusive) sowie Schrittweite vorgeben
np.arange(start=1, stop=11, step=2.5)
# Zufallszahlen: Gleichverteilung
np.random.uniform(0,1,size=(2,2))
Arrays aus Dateien einlesen¶
Bevor wir jetzt viele Beispiele behandeln: Die meisten Pythonpakete, die regelmäßige, mehrdimensionale Daten aus Dateien einlesen, geben diese als ndarray zurück. Das können Pakete zum Einlesen von Rasterdaten, Bildern usw. sein. Wir lernen nun ein besonderes Format kennen, das im wissenschaftlichen Bereich große Bedeutung gewonnen hat: das NetCDF-Format ("Network Common Data Form").
Anwendungsbeispiel: Schneeklimatologie in Europa mit ERA5¶
ERA5 ist das jüngste globale Reanalyseprodukt des ECMWF (European Centre for Medium-Range Weather Forecasts). Aber was ist eigentlich eine Reanalyse? Schaut Euch bitte zunächst das folgende Video an, dass wir mit etwas jupyter-Hokuspokus direkt einbinden können.
from IPython.display import HTML
HTML('<iframe width="560" height="315" src="https://www.youtube.com/embed/FAGobvUGl24" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>')
Wir verwenden in diesem Kurs "ERA5-Land", ein räumlich höher aufgelöstes Spezialprodukt, welches Klimavariablen für die Landoberfläche bereitstellt. Die Daten sind zwar stündlich, aber wir nutzen das Produkt mit monatlichen Mittelwerten, um die Datenmenge zu reduzieren. Auch nutzen wir nur ein Fenster über Europa.
Die Daten können hier heruntergeladen werden - Ihr müsst Euch für den Download allerdings bei Copernicus registrieren. Aber das Formular für die Auswahl der Daten könnt Ihr Euch auch so anschauen. Eine Beschreibung der verfügbaren Parameter aus ERA5-Land gibt es hier.
Wir haben für unser Beispiel die Parameter Schneebedeckung (snowc) und Temperatur in 2m Höhe (t2m) heruntergeladen. Das sind für Europa allein immerhin schon über 300 MB.
Lesen der Daten aus einer NetCDF-Datei¶
Ohne hier in die Tiefe zu gehen, lernen wir ein wichtiges Datenformat zur Speicherung mehrdimensionaler Daten kennen, das netcdf-Format. Wir nutzen dazu das Paket netCDF4.
import netCDF4 as nc
era5 = nc.Dataset("../data/era5_2mtemp_and_snowcover.nc", "r", format="NETCDF4")
Das Besondere am NetCDF-Format ist, dass die Daten bereits entlang der Dimensions strukturiert sind. Diese Dimesionen kann man sich wie folgt anzeigen lassen:
era5.dimensions
Wir haben also die Dimensionen latitude, longitude und time. Entlang dieser Dimensionen kann eine NetCDF-Datei beliebig viele Variablen (i.e. Daten) bereithalten. Einen Überblick gibt uns das Attribut variables.
era5.variables
Aufgabe¶
Du siehst, dass auch die Dimensionen als Variablen abgelegt sind. Schau Dir nun den Output des Befehls era5.variables genauer an: Welche Einheiten haben die Variablen - und welchen shape?
Lösung¶
longitude, unit: degrees east, shape: (401,)latitude, unit: degrees north, shape: (401,)time, unit: hours since 1900-01-01 00:00:00.0, shape: (485,)t2m(2 metre temperature), units: Kelvin, shape: (485, 401, 401)snowc(Snow cover), unit: %, shape: (485, 401, 401)
Analyse der Schneebedeckung¶
import matplotlib.pyplot as plt
Um einen groben Überblick über die räumlichen Verhältnisse zu erhalten, berechnen wir zunächst den Mittelwert der Schneebedeckung (snowc) über den gesamten Zeitraum für jede Gitterzelle. Da die Zeit die erste Dimension ist, berechnen wir den Mittelwert (mean) entlang der ersten Dimension (axis=0).
Wir sehen an diesem Beispiel auch gleich, wie wir auf die Daten im NetCDF zugreifen: {NetCDF-Objekt}["{Variable}"][:].
Das nachgestellte [:] ist der Schlüssel, um auf die Daten als ndarray zuzugreifen. Von da an ist alles Routine...
snowc_time_avg = era5["snowc"][:].mean(axis=0)
Eine schnelle Möglichkeit zum Plotten regelmäßiger Gitter bietet die matplotlib-Funktion imshow.
cp = plt.imshow(snowc_time_avg)

Wir würden hier gern noch die Achsen mit sinnvollen Ticklabels versehen. Dafür gibt es unterschiedliche Kniffe. Wir geben hier einfach die räumliche Bounding Box ([x_min , x_max, y_min , y_max]) an, die wir aus den Variablen latitude und longitude konstruieren.
bbox = [era5["longitude"][:].min(),
era5["longitude"][:].max(),
era5["latitude"][:].min(),
era5["latitude"][:].max()]
Also nochmal in schicker...
fig = plt.figure(figsize=(8,8))
cmap = plt.cm.get_cmap("Greens_r").copy()
cmap.set_bad('black',1.)
cp = plt.imshow(snowc_time_avg, extent=bbox, cmap=cmap)
#fig.set_facecolor("black")
plt.xlabel("Latitude")
plt.xlabel("Longitude")
plt.grid()
plt.colorbar(cp, shrink=0.8)
_ = plt.title("Average snow cover (%) from 1981-2021")

Aufgabe¶
Stelle nun den Zusammenhang zwischen Breitengrad und Schneebedeckung dar, mit anderen Worten: Berechne den Mittelwert der Schneebedeckung entlang der Dimensionen time und longitude und plotte dann den resultieren 1-D Array gegen die Dimension latitude. Hinweis: Das axis-Argument kann mehrere Dimensionen enthalten. Mit axis=(0,1) "reduziert" man z.B. die Dimensionen 0 und 1 gleichzeitig.
Lösung¶
snowc_time_long_avg = era5["snowc"][:].mean(axis=(0,2))
plt.plot(era5["latitude"][:], snowc_time_long_avg)
plt.xlabel("Latitude")
plt.ylabel("Avg. snow cover (%)")
plt.grid()

Vertiefungsaufgabe¶
Mal wieder Klimawandel: Stelle den zeitlichen Verlauf der mittleren Schneebedeckung dar. Dafür brauchst Du einen datetime Array. Die Variable time ist ein bisschen spröde...sie stellt Stunden seit dem 1. Januar 1900 dar. Die Umwandlung in einen Array von datetime schenken wir Dir...und nehmen pandas zur Hilfe.
import pandas as pd
dtimes = pd.to_datetime(era5["time"][:].astype(np.int64)*3600, unit="s", origin="1900-01-01T00:00:00")
Anmerkung: Wer sich fragt, warum wir nochmal eine Typkonvertierung mit astype(np.int64) machen, kann diese ja mal rauslöschen und schauen, was passiert. Stichwort: Overflow. Die Aufklärung für Streber:innen gibt es passenderweise bei Stackoverflow. Gut, dass wir wissen, was Datentypen sind...
So, jetzt bist Du dran!
Lösung¶
snowc_lat_long_avg = era5["snowc"][:].mean(axis=(1,2))
plt.rcParams.update({'font.size': 14})
plt.subplots(figsize=(12,5))
plt.plot(dtimes, snowc_lat_long_avg)
plt.xlabel("Time")
plt.ylabel("Avg. snow cover (%)")
plt.grid()

Wir sehen hier einen klaren Jahresgang, vielleicht auch einen gewissen Trend über die Zeit? Naja, ganz schön schwierig mit den Trends, vor allem wenn die Reihe "nur" 40 Jahre lang ist. Außerdem ist zu bedenken: Es geht um Schneebedeckung, nicht um Schmelzwasseräquivalente...naja. Vertagen wir das Thema.
Wer noch Lust hat, kann ja mal ein paar statistische Kennwerte über die Zeit für eine Teilregion betrachten - sagen wir mal eine grobe Definition für Mitteleuropa: alles zwischen 5 und 15 Grad West und 45 und 55 Grad Nord.
i = np.where(era5["latitude"][:]==55.)[0][0]
j = np.where(era5["latitude"][:]==45.)[0][0]
k = np.where(era5["longitude"][:]==5.)[0][0]
m = np.where(era5["longitude"][:]==15.)[0][0]
i, j, k, m
snowc_me = era5["snowc"][:,i:j, k:m].mean(axis=(1,2))
Für die Statistik packen wir das lieber in einen DataFrame.
df = pd.DataFrame({"snowc":snowc_me}, index=dtimes)
Jetzt wollen wir für jedes Jahr den Mittelwert und das Maximum der Schneebedeckung darstellen.
# Das letzte Jahr schmeißen wir raus, weil unvollständig
dfmean = df.resample("1a").mean()[:-1]
dfmax = df.resample("1a").max()[:-1]
plt.rcParams.update({'font.size': 14})
fig, ax = plt.subplots(figsize=(12,5))
plt.plot(dfmean.index, dfmean.snowc, color="tab:blue", lw=1.5, label="Mean SC per year")
plt.plot(dfmax.index, dfmax.snowc, color="tab:red", lw=1.5, label="Max. SC per year")
plt.xlabel("Time")
plt.ylabel("Snow cover (%)")
plt.legend()
plt.grid()

Naja, sieht ein bisschen langweilig aus...aber so ist das eben manchmal.
Alles noch einfacher und mächtiger mit xarray¶
Wir haben die NetCDF-Datei mit dem Paket netCDF4 eingelesen. Es gibt mittlerweile ein neues Paket, welches das Arbeiten mit NetCDF-Dateien dramatisch erleichtert: xarray. Im Prinzip könnt Ihr Euch xarray wie eine Kombination aus NetCDF4 und pandas mit einer Vielfalt hilfreicher Werkzeuge (Methoden) vorstellen. Am Beispiel:
import xarray as xr
ds = xr.open_dataset("../data/era5_2mtemp_and_snowcover.nc")
ds
# Mittelwert über den Gesamtzeitraum
ds["snowc"].mean(axis=0).plot()

# Zeitreihe für die Gitterzelle, in der sich Potsdam befindet
df = ds.sel(latitude=52.38, longitude=13.06, method="nearest")["snowc"]
df.plot()
