Zu Hause bei Python!¶
Wenn Ihr dieses Notebook geöffnet habt, seid Ihr schon mittendrin in der Python-Welt!
Hallo Python!¶
Python ist eine interpretierte Sprache - so wie auch R oder Matlab. Im Gegensatz zu kompilierten Sprachen (so wie C, C++ oder Fortran) wird jedes Kommando sofort ausgeführt ("interpretiert"). Wie beim Militär!
Die Ausführung erfolgt in juypter, indem man mit sich mit dem Cursor auf eine ausführbare Zelle bewegt und dann in der Toolbar das "Run"-Button drückt. Alternative: Shift + Enter.
Beispiel Wir nutzen den "print"-Befehl, um eine Ausgabe im "Hallo Welt"-Stil zu erzeugen (traditionell die erste Operation beim Erlernen einer Programmiersprache). Führt dazu folgende Zelle wie beschrieben aus!
print("Hallo Python.")
Aufgabe¶
Schreibe Dein eigenes "Hallo" statement in die folgende Zelle und führe es aus.
Lösung¶
print("Hallo irgendwas anderes.")
Python als Taschenrechner¶
Ihr wisst nun, wie man eine juypter-Zelle ausführt. Anstatt jetzt einen print-Befehl auszuführen, könnt Ihr auch einfache Rechenoperationen in einer Zelle ausführen. Das Ergebnis der Operation gibt jupyter direkt aus.
1+1
2**3
Aufgabe¶
Berechne in der folgenden Zelle das Ergebnis der Operation $\left ( \frac{22}{11} * (1 + 5) \right )^2$. Tipp: Der Operator für eine Potenz ist in Python **.
Lösung¶
((22 / 11) * (1 + 5))**2
Einige Funktionen in jupyter¶
Die Funktionsleiste oben stellt Euch die wichtigsten Funktionalitäten von jupyter zur Verfügung, die Ihr zum navigieren und arbeiten braucht. Bewege die Maus über die obigen Buttons, um zu sehen, was für eine Funktion sie haben: 
Aufgabe: Füge eine Zelle unter dieser Zelle ein, schreibe eine Rechenoperation hinein, führe sie aus, verschiebe die Zelle nach oben und unten und lösche sie dann wieder.
Es gibt aber auch jeden Menge Tastenkombinationen, um Euch das Leben zu erleichtern (oder schwerer zu machen?). Einen Überblick bekommmt Ihr über das rechte Button, das wie eine Tastatur aussieht (open the command palette).
Markdown in jupyter¶
Markdown kennst Du ja schon. Ein schlanke Sprache, um übersichtlich formatierten Text zu erstellen. In jupyter kannst Du Markdown direkt in die Zellen schreiben und dann "rendern" (also hübsch formatiert darstellen). Dafür musst Du jupyter aber erst mitteilen, dass in der Zelle Markdown steht. Markiere dafür die Zelle (links vom eigentllichen Text) und wähle dann im Dropdown-Menü des Toolbars "Markdown".
Führe dann die Zelle mit Run (oder Shift + Enter) aus.
Aufgabe¶
Doppelklicke auf folgende Zelle. Du siehst nun das "rohe" Markdown. Drücke auf Run, um die Zelle wieder zu rendern. Füge nun der Markdown-Zelle folgende Elemente hinzu: (i) Ein weiteres Listenelement, (ii) Eine weitere Codeblockzeile, (iii) einen weiteren funktionierenden Hyperlink, (iv) eine weitere Überschriftenebene.
Dies ist eine Markdown-Zelle¶
Eine Auflistung¶
- Item 1
- Item 2
Ein Code-Block¶
a = 1 + 1
print("Hallo Welt!")Ein Link¶
Den Moodle-Kurs findet Ihr unter diesem Link.
Lösung¶
- (i) Ein weiteres Listenelement
(ii) Eine weitere Codeblockzeile(iii) einen weiteren funktionierenden Hyperlink
(iv) eine weitere Überschriftenebene.¶
Nochmal ein paar Schritte zurück...¶
jupyter ist ein sehr fortgeschrittenes Werkzeug, das es erlaubt, Code zu strukturieren, mit weiteren Inhalten anzureichern und interaktiv zu arbeiten. Dadurch wird aber verborgen, was Python im Kern ist: Ein Interpreter, der Codeanweisungen interpretiert. Eine viel "rohere" Art und Weise, Python zu nutzen besteht darin, die sogenannte Python-Konsole direkt aufzurufen. Dies erfolgt über die Kommandozeile von DOS (MS Windows) oder die bash (Linux).
Aufgabe
- Öffnet bitte ein entsprechendes Terminal auf Eurem Rechner (DOS oder bash).
- Führt den Befehl
pythonaus. - Was Ihr nun seht ist das sogenannte "Pythonprompt", also die Möglichkeit, Pythoncode einzugeben.
- Schreibt mal eine "Hallo Welt"-Anwendung ins Prompt (siehe oben)
- Benutzt das Prompt als Taschenrechner.
- Schließt die Pythonkonsole mit dem
exit()-Befehl.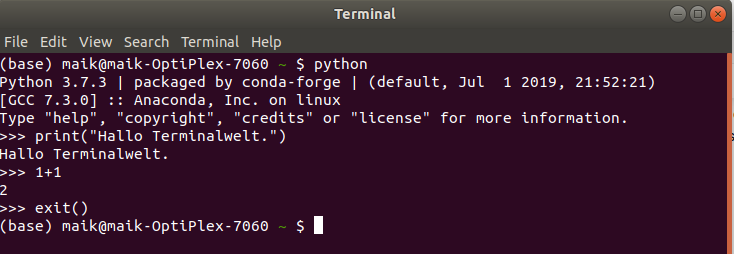
Dieses Nutzungszenario ist relativ selten. Weiter verbreitet ist hingegen das Erstellen und Ausführen sogenannter Skripte: Dazu schreibt man eine Abfolge beliebiger Pythonbefehle in eine Textdatei und führt die ganze Datei mit Python aus. Auf diese Art und Weise kann man ganze Arbeitsabläufe automatisieren. Wir kommen vielleicht später noch darauf zurück...in diesem Kurs werden wir aber vor allem mit jupyter arbeiten.
Mit Variablen arbeiten¶
Die Zuweisung von Variablen und das Arbeiten mit diesen Variablen ist ein wesentliches Element der Programmierung. Wir kennen das Konzept der Zuweisung aus der Mathematik:
a = 1
b = 1
c = a + b
# Die folgende Zeile sorgt dafür, dass der Wert von c ausgegeben wird.
c
Hoppla, wir haben gannz nebenbei das Konzept der Kommentarzeile kennengelernt. Stellt man einer Codezeile das #-Zeichen voran, wird diese vom Interpreter ignoriert. Auf diese Weise kann man den Code erläutern - das werdet Ihr noch häufig sehen.
Im Prinzip ist das Zuweisen von Variablenwerten und das Arbeiten mit Variable intuitiv. Für Neulinge mag aber überaschend sein, dass die Zuweisung sich nicht auf numerische Werte beschränken muss.
# Zuweisung einer Zeichenkette
a = "Rosalind"
b = "Franklin"
a, b
Das man Zeichenketten in Python mit dem +-Operator verketten kann, sei hier nur am Rande erwähnt:
a + " " + b
Aufgabe¶
Wer war Rosalind Franklin?
Lösung¶
Das kannst Du wirklich selbst recherchieren.
Der type einer Variable¶
Es gibt unterschiedliche Datentypen, die wir zuweisen können. Den Datentyp einer Variable können wir über den type Befehl abfragen:
a = 1
b = "Rosalind"
c = 1.5
d = True
type(a), type(b), type(c), type(d)
Aufgabe¶
Einige Datentypen kann man durch Operationen sinnvoll verknüpfen, andere nicht. Verknüpft in der nächsten Zelle paarweise die Variablen a, b, c und d mit dem +-Operator. Erläutert Eure Beobachtungen.
Lösung¶
a + b:TypeError: unsupported operand type(s) for +: 'int' and 'str'a + c:int+floatergibt einfloata + d: einboolmit dem WertTrueverhält sich wie einintmit dem Wert1b + c:TypeError: can only concatenate str (not "float") to strb + d:TypeError: can only concatenate str (not "bool") to strc + d: einboolmit dem WertTrueverhält sich wie einintmit dem Wert1
Selber machen lassen: Die Lösung kommt als Paket.¶
Man kann sich für alle Anwendungsfälle eine eigene Lösung zurechtprogrammieren. Oft haben andere das aber schon besser gemacht. Das Ergebnis kann man sich als "Paket" (package) (Synonym: Bibliothek/library) importieren und direkt nutzen. Es gibt Pakete für alles: numerische Operationen, Dateisystemoperationen, Graphikerstellung, Statistik - es gibt fast nichts, was es fast nicht gibt.
Beispiel: Wir importieren das os-Paket. Damit kann man Aufgaben erledigen, die Bezug zu den Aufgaben des Betriebssytems haben.
import os
Das war's schon. Wir überprüfen mal eine Funktion, die uns os zur Verfügung stellt und lassen uns sagen, in welchem Arbeitverzeichnis unser notebook sich gerade befindet:
os.getcwd()
Das sieht bei Euch natürlich anders aus als bei mir, weil Ihr das repository anderswo gespeichert habt. Wichtig für Euch ist: Die Funktionen eines importierten Moduls kann man mit modulname.funktionsname ansprechen. Mehr zu Funktionen dann später!
Auf Dateien zugreifen (I/O)¶
Das Arbeiten mit Daten beinhaltet meist den Zugriff auf Dateien, welche diese Daten bereitstellen. Das Lesen und Schreiben von Daten bzw. Dateien ist naturgemäß eine zentrale Komponente der Datenverarbeitung. Zwei Aspekte sind dabei wichtig:
- Wo befindet sich eine Datei?
- Mit was für einem Inhalt rechne ich? Hier kommen die Begriffe "Dateiformat" und "Datenmodell" ins Spiel: Ein Dateiformat wäre z.B. eine Textdatei, ein Datenmodell wäre eine Tabelle. Eine
csv-Datei ist z.B. typischerweise eine Textdatei mit einer Tabelle, in der die Spalten mit einem Komma oder einem Semikolon getrennt sind. Einexlsx-Datei wiederum ist eine binäre Datei, die wiederum eine Tabelle enthält.
Aber bevor wir noch lange weiterreden: Schauen wir uns mal das Verzeichnis an, in dem Ihr arbeitet.
01_environment
|___data
| example-file-3.txt
| ...
|___R
| ...
|___python
|___data
| example-file-2.txt
| tour-de-python.ipynb
| example-file-1.txt
| ...
| README.md
| ...Wo befindet sich die Datei, die ich Lesen oder Schreiben möchte?¶
Der Speicherort einer Datei wird über den "Pfad" angegeben. Man unterscheidet zwischen "absoluten" und "relativen" Pfadangaben. Der relative Pfad setzt gibt den Speicherort relativ zum Arbeitsverzeichnis an. Wenn Ihr ein jupyter notebook öffnet, entspricht das Arbeitsverzeichnis dem Speicherort der notebook-Datei.
Versuchen wir einmal eine Datei im gleichen Verzeichnis zu lesen. Wir nutzen dazu die Befehle open, read und close.
# Datei öffnen
file = open("example-file-1.txt", "r")
# Datei lesen
content = file.read()
# Datei schließen
file.close()
# Dateinhalt ausgeben
print(content)
Das Argument "r" in open teilt Python mit, dass wir aus der Datei lesen möchten (nicht in sie schreiben). Nun öffnen wir die Datei example-file-2.txt, die in dem Unterverzeichnis data relativ zu unserem notebook liegt.
# Datei öffnen
file = open("data/example-file-2.txt", "r")
# Datei lesen
content = file.read()
# Datei schließen
file.close()
# Dateinhalt ausgeben
print(content)
Aller guten Dinge sind drei: Nun greifen wir über einen relativen Pfad auf eine Datei zu, die nicht in unserem Arbeitverzeichnis liegt, sondern in dem data-Verzeichnis, welches eine Ebene darüber liegt. Übergeordnete Verzeichnisebenen spricht man mit dem ..-Element an.
# Datei öffnen
file = open("../data/example-file-3.txt", "r")
# Datei lesen
content = file.read()
# Datei schließen
file.close()
# Dateinhalt ausgeben
print(content)
Absolute Pfadangaben¶
Bislang haben wir immer relative Pfadangaben (relativ zum Arbeitsverzeichnis) genutzt. Wenn man auf Dateien zugreifen möchte, die auf dem Rechner "weit weg" vom Arbeitsverzeichnis liegen, können solche relativen Pfade aber sehr mühsam umzusetzen sein. Man kann auch einfach den vollständigen (absoluten) Pfad zu einer Datei angeben. Dieser ist dann aber auf jedem System anders, weil jeder auf seinem Rechner andere Verzeichnisstrukturen hat. Der absolute Pfad zu meiner Datei example-file-1.txt lautet zum Beispiel: /media/x/teach/MSc_UmweltDV/umweltdv/01_environment/python/example-file-1.txt.
Aufgabe¶
Wie lautet der absolute Pfad zu dieser Datei auf Eurem System? Lest den Dateiinhalt in der unten stehenden Zelle unter Nutzung einer absoluten Pfadangabe.
Lösung¶
# Datei öffnen
# In der folgenden Zeile müsst Ihr natürlich den Pfad auf Eurem Rechner eintragen
file = open("/media/x/teach/MSc_UmweltDV/umweltdv/01_environment/python/example-file-1.txt", "r")
# Datei lesen
content = file.read()
# Datei schließen
file.close()
# Dateinhalt ausgeben
print(content)
Wie ich die Datei öffne, hängt vom Inhalt ab, den ich erwarte!¶
Wir haben eben bereits Textdateien geöffnet und gelesen. Dabei haben wir einfach den gesamten Inhalt komplett gelesen und ausgegeben. Meist wollen wir den Dateiinhalt jedoch interpretieren. Oft wird in Textdateien eine Tabelle abgelegt, deren Spalten mit Zeichen wie ; oder , getrennt sind. Man kann sich natürlich die Interpretation solcher Dateien selbst zusammenprogrammmieren, aber andere haben das schon besser für uns gemacht.
Wir haben ja schon gelernt, wie man ein Paket importiert. Zur Verarbeitung von Tabellendaten nutzen wir das Paket pandas. Lesen wir doch mal eine Tabelle mit pandas ein:
import pandas
df = pandas.read_csv("../data/example-table.csv", sep=";")
df
Im nächsten Termin werdet Ihr mehr über pandas lernen.
Grafiken erstellen¶
In diesem Kurs werden wir uns noch oft und ausführlich mit der Erstellung von Grafiken beschäftigen. Jetzt nur ganz kurz, weil wir gerade schonmal Daten aus einer Tabelle im Arbeitsspeicher haben...
# So importieren wir das Kernmodul aus dem Grrafikpaket matplotlib
import matplotlib.pyplot as plt
# Wir teilen juypter mit, dass wir die Plots direkt ins notebook einbinden möchten.
%matplotlib inline
plt.plot(df.temperature, df.saturation)
plt.grid()
plt.xlabel("Temperatur (degC)")
plt.ylabel("Sättigungsdampfdruck (hPa)")
_ = plt.title("Sättigungsdampfdruck über Wasser (Magnus-Formel)")

Mehr dazu in den kommenden Wochen!
Zu Hilfe!!¶
Hilf mir es allein zu tun.
Dieses Zitat von Maria Montessori trifft natürlich auch auf die Programmierung zu. Hilfe finden, um Probleme zu lösen - das ist sicherlich die Schlüsselkompetenz. Nur die wenigstens wissenschaftlichen Python-Nutzer sprechen fließend Python, sondern stückeln sich ihren Code so gut es geht zusammen.
Hilfe in juypter¶
In einer Python-Umgebung (also auch in jupyter), kann man sich über Funktionen über help informieren.
# Hilfe zum print-Befehl
help(print)
jupyter bietet aber mehr. Der Schlüssel ist die Tab-Taste (Tabulator). In einer Code-Zelle könnt Ihr zu jedem Zeitpunkt Tab drücken und juypter bietet Euch dann Optionen an oder vervollständigt den Code.
Aufgabe¶
- Gib in der folgenden Zelle
prein und drücke dannTab. Was passiert? - Lösche die Zelle wieder, gib
priein und drücke dannTab. Beobachtung?
Lösung¶
Mit der Tab-Taste kann man sich Vorschläge für die Verrvollständigung eines Befehls holen.
Aufgabe¶
Noch besser wird es, wenn ihr Hilfe über den Aufruf einer Funktion erhalten möchtet. Nutzt dazu die Tastenkombination Shift + Tab, nachdem Ihr einen Befehl/eine Funktion eingegeben habt, zu der Ihr HIlfe erhalten möchtet.
- Gebt in der folgenden Zeile den Befehl
printein und drückt dannShift + Tab. Beobachtung? - Drück nun
Esc, haltetShiftgedrückt und drückt zweimalTab. Was ist der Unterschied?
Lösung¶
Einmal Shift + Tab zeigt die Überschrift (Header) der Hilfe zu einer Funktion an, zweimal Shift + Tab klappt die Hilfe aus (und viermal dockt sie unten an).
Hilfe im Netz¶
jupyter bietet bequemen Zugang zur eingebauten Python-Hilfe. Oft löst das aber nicht das Problem zum Verständnis der Funktion oder Lösung eines Problems. Fast genau so oft hatten aber andere Menschen schon das gleiche Problem und sich online Hilfe geholt. Eine der besten Hilfeplattformen ist stackoverflow. Dort landet man bei einer normalen Websuche nicht selten. Aber es gibt auch andere Plattformen, auf denen Du Antworten auf Deine Fragen finden magst.
Tipp: Suche auf Englisch - so findet Du meist die hilfreicheren Quellen.
Fehler sind eine Hilfe!¶
Oft erzeugen Fehlermeldungen lange Gesichter. Aber fürchte Dich nicht. Freue Dich, dass Python versucht, Deinen Code in Ordnung zu bringen. Wenn Du mit der Fehlermeldung nichts anfangen könnt, kopiere sie einfach in eine Websuche und lasse Dir dort die Lösung servieren.
Aufgabe¶
Führe die folgenden Zellen aus und überlege, was die Fehlermeldungen Dir sagen. Versuche die Fehler zu korrigieren, so dass der Code ausgeführt wird.
print(Hallo Welt)
print "Hallo Welt"
file = open("example-file1.txt")
file.close()
Lösung¶
# Die richtigen Befehle lauten
# Anführungsstriche fehlten
print("Hallo Welt")
# Klammern fehlten
print("Hallo Welt")
# Dateiname war falsch
file = open("example-file-1.txt")
file.close()
Zum Weiterarbeiten¶
Es gibt einige tolle Quellen, welche die Inhalte dieses Blocks vertiefen und erweitern.
Vertiefung in der Coding-Werkstatt¶
Bearbeite zunächst die Übungsaufgaben zu dieser Lektion, denn in den Übungsaufgaben wirst Du einen weiteren wichtigen Datentyp in Python kennenlernen: die Liste (list). Beispiele für eine Liste:
nottodolist = ["Frühzeitig an die eigene Rente denken.",
"Glastüren übersehen.",
"Etwas kaufen, weil es »Aloe Vera« enthält."]
ichzaehlbis3 = [1, 2., "drei"]
# Länge einer Liste
len(nottodolist)
# Zugriff auf Elemente einer Liste
nottodolist[0]
# Schleife über Elemente eine Liste
for item in nottodolist:
print(item)
Der Dictionary (dict)¶
In dieser Vertiefung lernen wir einen weiteren wichtigen Datentyp in Python kennen: den Dictionary (dict). Er wird im Gegensatz zur Liste mit geschwungenen Klammern eröffnet. Er enthält Schlüsselwörter (keys) und für jedes Schlüsselwort (key) einen Wert.
article = {"title": "River flow forecasting through conceptual models part I — A discussion of principles",
"authors": ["Nash, J. E.", " Sutcliffe, J. V."],
"journal": "Journal of Hydrology",
"year": 1970}
# Die Elemente eines Dictionary kann man über Schlüsselwörter aufrufen.
article["title"]
# Übersicht aller Schlüsselwörter
article.keys()
# Hinzufügen neuer Elemente
article["volume"] = 10
article["issue"] = 3
article["firstpage"] = 282
article["lastpage"] = 290
article
Jetzt bis Du dran: Erfassung und Abfrage von Radiosonden-Metadaten¶
Radiosondenaufstiege dienen der vertikalen Vermessung des Zustands der Atmopshäre. Der Deutsche Wetterdienst (DWD) betreibt 14 aktive Stationen, an denen regelmäßig Radiosondenaufstiege erfolgen (die Ballone, an denen die Sonden hängen, platzen dann in einer bestimmten Höhe und die Sonden kommen dann irgendwo wieder runter).
Die Metadaten der einzelnen Stationen hält der DWD hier vor. Wir haben für unser Beispiel mal die Metadaten der Station Bergen (Rügen) runtergeladen - Ihr findet Sie im Verzeichnis ../data/Meta_Daten_pkt_aero_00368/ in mehreren Dateien.
Eure Aufgabe besteht nun aus folgenden Schritten:
- Liste der Attribute erstellen: Schaut Euch zunächst die Dateien an. Erstellt nun eine Liste (
list) namensattributes, welche die Bezeichner der Metadatenattribute enthält (z.B."Stations_ID") - Werte für die einzelnen Attribute eintragen: Der untenstehende Codeblock fragt Dich nun nach den Werten der Attribute für die Station Bergen. Dazu wird die Funktion
inputverwendet. Diese Funktion erfordert eine Nutzereingabe und überträgt diese Nutzereingabe auf eine Variable (hier:value). Wenn Ihr also nach dem Wert gefragt werdet, müsst Ihr ihn aus den Dateien ablesen und eintragen. Hinweis: Gebt immer nur den aktuellsten Wert ein, nicht die Historie der Metadaten der Station. Die Funktionevalmüsst Ihr noch nicht unbedingt verstehen - wir versuchen damit die Nutzereingabe (eine Zeichenkette) in einen geeigneten Datenyp umzuwandeln (also z.B.float). Ihr müsst in dem Codeblock nun noch eine Zeile ergänzen, so dassvalueauch wirklich in den dictionarymetadataübertragen wird. Natürlich ist dieses Skript nur dazu da, um Möglichkeiten für Nutzereingaben zu demonstrieren. Ihr könnt natürlich alternativ auch direkt die Definition desmetadata-Dictionary aufschreiben. - Dictionary anschauen: Schaut Euch den Zustand Eures Dictionay
metadataan. - Werte und Datentyp ausgewählte Attribute ausgeben: Dieser Codeblock zeigt Dir die verfügbaren Attribute in
metadataan und erlaubt es Dir, ein Attribut Eurer Wahl anzugeben. Für dieses wird dann Wert und Datentyp ausgegeben.
Liste der Attribute erstellen¶
# Definiere hier die Liste mit Attributen
attributes =
Werte für die einzelnen Attribute eintragen¶
# Dies ist der Dictionary, in dem die Werte der Attribute gesammelt werden - noch ist er leer...
metadata = {}
# Nun gehen wir alle Attribute aus attributes durch...
for attribute in attributes:
value = input("Geben Sie einen Wert für das Attribut %s an der Station Bergen ein: " % attribute)
try:
value = eval(value)
except:
pass
# HIER MUSST DU EINE ZEILE ERGÄNZEN!
Dictionary anschauen¶
# Was musst Du hier eintragen, um Dir den Dictionary anzuschauen?
Werte und Datentyp ausgewählter Attribute ausgeben¶
print("Folgende Attribute stehen zur Verfügung:")
for attribute in metadata.keys():
print(" - %s" % attribute)
attribute = input("Über welches Attribut möchtest Du Dich informieren? ")
print("")
print("---")
print("Ergebnis der Abfrage für Attribut %s:" % attribute)
# Hier musst DU nun weitere print-statements einfügen,
# mit denen Wert und Datentyp dieses Attributs ausgedruckt werden: